B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





First and foremost, vMSC stands for vSphere Metro Storage Cluster, that is, a vSphere HA/DRS cluster stretched over distance. After attending Duncan Epping & Lee Dilworth's presentation at VMworld 2013 on vSphere Metro Storage Clusters (Session BCO4872, see above video), it got me thinking about writing this article.
The use case for vMSC is pretty clear….to provide VM mobility and resilience across data centers. As a storage practitioner for 12 years, one of the achilles heels of Inter-Data Center Failover has been not only the Ethernet network, but also the storage replication mechanism used. Maintaining consistent IP connectivity during and after failover events can present complications, but these can be surmounted using Layer-2 LAN extensions, DNS and other technology.
Meeting the challenge using (pretty dumb) array-based replication just doesn't cut it, in terms of making for seamless failover/failback of the compute function. Software like SRM is a great solution for meeting the challenge of planned failover with some downtime in an orchestrated manner.
Most would acknowledge there is a big difference between disaster recovery and fault tolerance. To recap, Fault Tolerance is not about N+1, N+2, or N+anything. It requires a solution that ensures zero disruption, with zero operational intervention. That applies to any system, either hardware or software. It also applies to solutions.
Data center FT is the ability to withstand the failure of the entire data center (a term to describe a single set of systems in a single place) and not experience a blip, or notice anything discernible.
When we talk about stretch clusters, there are two consumable resources that need to be stretched:
Let’s evaluate a scenario to illustrate the challenges. We have the following topology:
This is what it looks like:
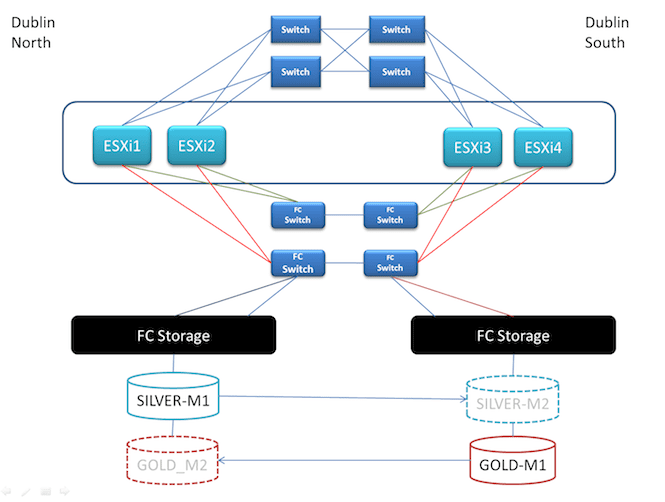 The deployment model is well understood. At all times a LUN in each device group is served from a single array, where it is only ever RW on one side. The LUN state changes when a failure occurs, or a planned failover migration is carried out. This is obviously a messy situation when a single site or interconnect between sites disappears. We can enter a split-brain scenario, where there is potential for data loss or data corruption. That's a longer discussion for another day, possibly in a future post.
The deployment model is well understood. At all times a LUN in each device group is served from a single array, where it is only ever RW on one side. The LUN state changes when a failure occurs, or a planned failover migration is carried out. This is obviously a messy situation when a single site or interconnect between sites disappears. We can enter a split-brain scenario, where there is potential for data loss or data corruption. That's a longer discussion for another day, possibly in a future post.
It's very surprising that this type of thing still goes on. But then this is the only way this setup can work.
Is there a better way ? Yes. In the Software Defined Data Centre anything is possible.
Let's go back in time. While vSphere was gaining prominence, Veritas was a mainstay in Enterprise Software, particularly in mission-critical UNIX environments. Veritas Volume Manager was a product used widely in SAN environments. It's primary role was to provide Software Raid, but it had a lot of features that were used for managing in-array, and intra-array replication and LUN presentation.
It was used in my experience to create a different, fault tolerant architecture that was simpler to manage.
When partnered with Veritas Cluster Server (VCS), it made for simple scalable clusters that could be stretched over distance. Back in the early 2000’s, it was possible to deploy up to a 32–node VCS cluster. This was mainly due to the proprietary cluster communication protocols that imposed a lower overhead.
So I'm going to use a this example to show what might be possible. Let's turn off array-based replication and in a way, treat the Storage Array like a JBOD device. This is a similar model to that being followed by VMware VSAN, bringing the capability back into the software.
In part 2 of the series I'm going to talk about how using an approach like this can solve many of these challenges and further demonstrate the benefits of the Software Defined DataCenter (SDDC).









